JOIN 原理
join方式连接多个表,本质就是各个表之间数据的循环匹配。
MySQL 5.5 版本之前,MySQL只支持一种表间关联方式,就是嵌套循环(Nested Loop Join)。如果关联表的数据量很大,则join关联的执行时间会非常长。
在MySQL 5.5 之后,MySQL通过引入BNLJ算法来优化嵌套执行。
1. 驱动表和被驱动表
对于内连接来说:
1
SELECT * FROM A JOIN B ON ···
在两个表都存在索引的情况下,小表驱动大表;
在只有一个索引的情况下,查询优化器会让有索引的表作为被驱动表;
Q:A一定是驱动表吗?
A:不一定优化器会根据你查询语句做优化,决定先查哪张表。先查询的那张表就是驱动表,可以通过
explain关键字查看对于外连接来说:
1
2
3SELECT * FROM A LEFT JOIN B ON ···
# 或
SELECT * FROM B RIGHT JOIN A ON ···通常,大家会认为A就是驱动表,B是被驱动表。但不一定。测试如下:
1
2
3
4
5
6
7
8
9CREATE TABLE a(f1 INT, f2 INT, INDEX(f1))ENGINE=INNODB;
CREATE TABLE b(f1 INT, f2 INT)ENGINE=INNODB;
INSERT INTO a VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
INSERT INTO b VALUES(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) WHERE (a.f2=b.f2);
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) AND (a.f2=b.f2) ;a表是有索引的,所以查询优化器会将外连接改造为内连接,将
a 有索引的表作为被驱动表执行;
2. Simple Nested-Loop Join(简单嵌套循环连接)
从表 A 中取出一条数据 1,遍历表 B,将匹配到的数据放到 result 以此类推,驱动表 A 中的每一条记录与被驱动表 B 的记录进行判断:
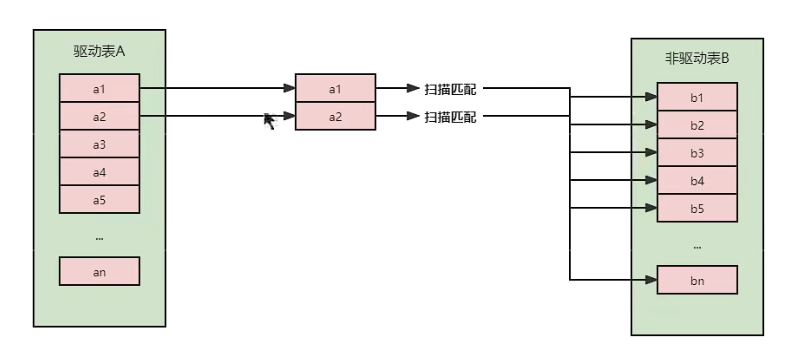
可以看到这种方式效率是非常低的,以上述表 A 数据100条,表 B 数据1000条计算,则 A * B = 10万次。开销统计如下:
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数: | 1 |
| 内表扫描次数: | A |
| 读取记录次数: | A+B*A |
| JOIN比较次数: | B*A |
| 回表读取记录次数: | 0 |
性能最差,所以MySQL对Nested-Loop Join 升级了后面两种优化算法。
3. Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join 其优化的思路主要是为了减少内层表数据的匹配次数,所以要求被驱动表上必须有索引才行。通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样极大的减少了对内层表的匹配次数。
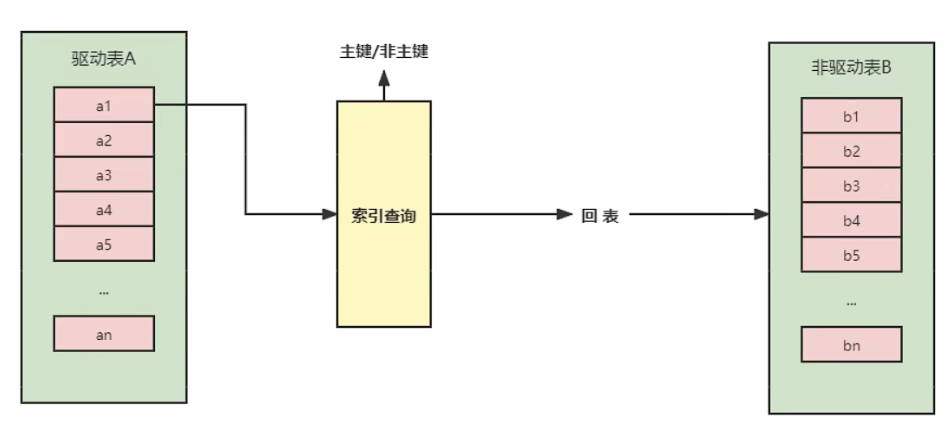
驱动表中的每条记录通过被驱动表的索引进行访问,因为索引的查询成本是稳定的,所以MySQL优化器倾向于使用记录数少的表作为驱动表(外表)。
如果被驱动表加索引,效率是非常高的,但如果索引不是主键索引,所以还得进行一次回表查询。相比,被驱动表的索引是主键索引。效率会更高。